


1、前实习生篡改代码攻击大模型训练,字节跳动起诉索赔800万
11月27日,南都记者获悉,字节跳动起诉前实习生田某某篡改代码攻击公司内部模型训练一案,已获北京市海淀区人民法院正式受理,案由为侵权责任纠纷。字节跳动请求法院,判令田某某赔偿公司侵权损失800万元及合理支出2万元,并公开赔礼道歉。
据南都记者了解,2024年10月,有媒体称“字节大模型训练任务被实习生攻击”,并有网传信息称“涉及8000多卡、损失上千万美元”。后字节跳动通过官方账号发布事实澄清,称确有实习生发生严重违纪,涉事实习生已于2024年8月被公司辞退。
上述澄清公告还指出,此次涉事行为恶意干扰的是,字节跳动商业化技术团队某研究项目的模型训练任务,并不影响公司的正式项目及线上业务,也不涉及字节跳动大模型等其他业务。至于“涉及8000多卡、损失上千万美元”的传闻,则属严重夸大。
11月5日,字节跳动内部发布的年内第四份《企业纪律与职业道德委员会通报》进一步披露了这起事件的相关细节。通报指出,2024年6月至7月,集团商业产品与技术部门前实习员工田某某,因对团队资源分配不满,通过编写、篡改代码等形式恶意攻击团队研究项目的模型训练任务,造成资源损耗。公司已与其解除实习协议,同步阳光诚信联盟及企业反舞弊联盟,并同步至其就读学校处理。(来源:南方都市报)
评论:田某某通过编写、篡改代码的形式恶意攻击公司的模型训练任务,已经对字节跳动的正常业务构成了实质性的干扰。尽管此次事件未影响公司的正式商业项目,但它对模型训练任务所造成的资源损耗是客观存在的,将导致公司为此付出大量的训练算力成本和人力成本。这种故意利用技术手段破坏企业内部正常运作秩序、损害企业合法权益的行为,完全符合侵权行为的构成要件,并且确实给字节跳动带来了实际的损害后果,甚至有存在构成刑事犯罪的可能。目前字节跳动以侵权责任纠纷作为案由提起诉讼,在法理上是有着坚实基础的。
但从情理上,田某某作为初入职场的年轻人,如果败诉不仅要承担巨额的赔偿责任,甚至可能成为失信被执行人,其个人的职业声誉也将遭受近乎毁灭性的打击。我们希望田某某可以诚恳地认识到自己行为的错误之处,积极地向字节跳动表达歉意并尽力弥补造成的损失,争取通过和解、调解的方式解决本案纠纷,让这件事朝着更具人性化、更有利于双方后续发展的方向妥善落幕。
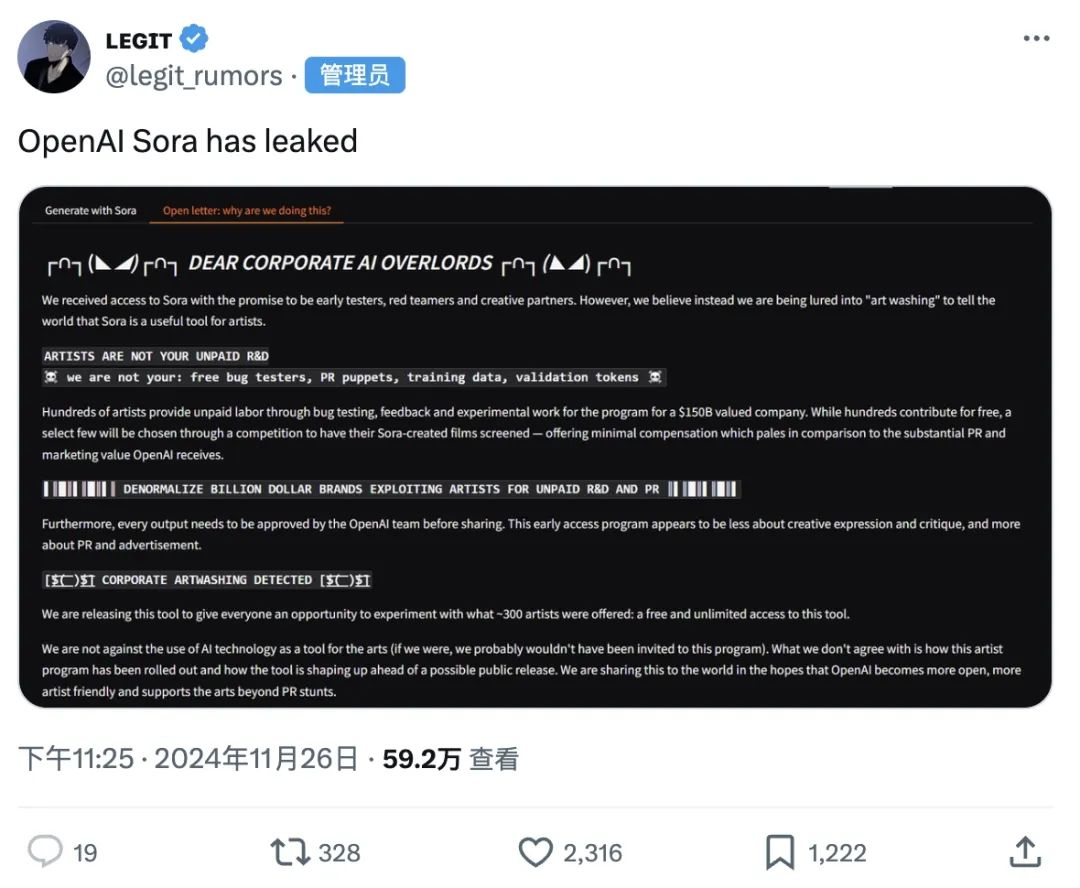
2、Sora突遭恶意泄露
自今年2月Sora曝光引发行业巨震后,近9个月的时间里OpenAI都没有任何关于Sora发布的消息,也一直未正式对外,仅对少数艺术家开放了试用权限。直到11月27日,Sora疑似被恶意泄露3小时,网上出现了不少新生成的视频。
11月27日凌晨,公共AI模型社区Hugging Face突然出现了一个文生视频的项目,一些据称参与了Sora测试的艺术家泄露了该模型的访问权限(API),以抗议OpenAI对他们的压榨行为。同时,艺术家发布了一封对OpenAI进行讨伐的公开信,控诉自己成为Sora的公关宣传工具。
此次泄露事件中的艺术家自称是“Sora PR Puppets”,他们在公开信中控诉“AI霸主”,指责OpenAI向早期测试人员施压,要求他们编造正面的叙述,实际上是在引诱大家参与“洗白”,向世人传递Sora是艺术家有用工具的信息,但并未给予他们应有的补偿。
在控诉信中他们表示,数百获得早期Sora访问权限的影视艺术家、技术人员,不停地测试这个产品,且创作内容在发布前要受到OpenAI的严格审核。与此同时,在众多贡献者中,只有少数通过比赛获胜的艺术家能够发布用Sora创作的影片,所获得的报酬微不足道,与OpenAI获得的巨额公关和市场推广价值完全不成比例。“我们认为,艺术家不是你们免费的研发团队,不是免费测试员、宣传傀儡、训练数据、验证工具。”公开信中表示,这个早期访问计划看起来更像是为了公关和宣传,而非真正的创意表达和批评。
3小时后,Sora关闭了所有对艺术家开放的访问权限。与此同时,有消息放出称OpenAI获得软银15亿美元的新投资,引发圈内新的讨论,这家AI巨头总是擅长制造新闻。(来源:第一财经)
评论:目前在AI行业,相关大模型产品在发布之前进行封闭测试、邀请性测试已经成为行业惯例,通过这种方式可以更有效的测试模型的能力,并对内容合规管理、收集改进意见等方面起到积极作用。OpenAI对Sora采取仅向少数艺术家开放试用权限的做法,本身是符合行业通行逻辑的,其初衷大概率也是希望在相对可控的环境下不断打磨产品,为后续正式推向市场做好充分准备。
然而,这些参与测试的艺术家选择恶意泄露Sora访问权限的做法,无疑是将自身置于一个危险的境地。从情理上来说,他们所控诉的诸如被压榨、报酬微薄、成为公关宣传工具等问题,确实反映出OpeanAI管理方面的不合理之处,艺术家们的内心不满是可以理解的。但他们在参与测试时已经与OpenAI签署了责任明确的保密协议,前述的不合理并不能成为保密责任的豁免例外。这些艺术家贸然打破保密规则,已经泄露了OpenAI的商业秘密,不仅可能会让他们面临来自OpenAI的巨额索赔,严重情况下甚至可能要承担相应的刑事责任。毕竟像Sora这样具有巨大商业潜力的产品,其访问权限等核心信息一旦泄露,可能会对OpenAI的市场竞争优势、后续产品布局等诸多方面产生难以估量的损害。仅凭义愤而以身犯险,实在是难谓理性。
3、微软澄清:不会使用用户的Word和Excel数据来训练AI模型
微软近日针对外界关于其使用用户Word和Excel数据训练AI模型的疑虑进行了官方澄清。
微软明确表示,公司不会使用用户的数据来训练其大型语言模型(AI模型)。此前有报道称,微软的“连接体验”功能可能会自动抓取用户在Word和Excel文档中的数据,用于AI模型训练,这引起了用户对个人隐私安全的担忧。微软强调,他们始终致力于保护用户的隐私和数据安全,任何功能的开发和运行都严格遵循相关的隐私政策和法律法规。
评论:用户数据及内容在AI时代已经成为了金矿,但多数平台只想免费开采。仅在2024年就发生了Meta、Adobe、X(Twitter)等多家平台强制性更新隐私政策要求使用用户内容进行数据训练的事件,每次都引起了不小的舆论风波,甚至引发监管机关的调查及处罚。相比之下,微软的澄清则显示出其在数据收集和使用过程中更加注重用户的选择权和知情权,通过明确表示不会使用用户数据训练AI模型,避免了类似的合规风险和用户争议,也体现了对用户的尊重。我们希望这可以成为一个正确的范例,AI行业要想长久的发展,必须重视和保障用户的隐私权益,更加谨慎地对待用户数据,推动整个行业建立起一套科学、完善且行之有效的数据使用规范与伦理准则。
4、网红抱怨AI网红抢走了她们的流量
Meta的Instagram出现了大量AI生成的网红,从真实模特和成人内容创作者窃取视频,替换为AI生成的脸,然后通过约会网站、Patreon、OnlyFans等货币化。成人内容创作者抱怨她们现在需要和AI网红竞争。网红Elaina St James称,自从Instagram上AI网红剧增之后,她的内容访问量大幅下降,从100万到500万次观看量下降到低于100万次,有时观看量不足50万次。她认为Instagram算法是部分原因,但AI网红也可能原因之一。她表示自己在与非自然事物进行竞争。(来源:Solidot)
评论:实际上使用AI换脸技术替换他人视频本身已经涉嫌侵犯个人信息及著作权。今年8月,北京互联网法院就公布了廖某诉某科技文化有限公司网络侵权责任纠纷的判决,被告某科技文化有限公司未经廖某授权同意,使用其出镜的系列视频制作换脸模板并上传至案涉软件中牟利,法院同样认定被告的行为虽未侵害原告的肖像权,但构成对原告个人信息权益的侵害,最终判决被告向原告书面致歉,并赔偿精神损失和经济损失。
虽然理论上相关换脸行为构成侵权,但对于自媒体而言,维权的时间及成本都过于高昂,多数情况下他们只能面对海量的涉嫌侵权账号默默忍受,成为新技术下被抛弃的“纺织女工”。我们希望平台面对这种情况下可以采取更加积极主动的法律措施,比如加大内容审核的力度,运用智能识别技术精准地筛查出那些利用AI换脸技术窃取他人视频、侵犯他人权益的内容,在源头上就将其拦截。同时,平台也应当建立起更加完善且便捷的投诉反馈机制,当像Elaina这样的真实网红发现自己的权益可能受到AI网红侵权影响时,能够迅速地向平台反映侵权情况,而平台则可以在短时间内作出回应并展开调查核实,如确认侵权属实,则应果断采取封禁账号、下架内容等措施,给被侵权人一个公正的交代。
- 相关领域
- 高科技与人工智能
