


1、《人工智能生成合成内容标识办法》发布
近日,为了促进人工智能健康发展,规范人工智能生成合成内容标识,保护公民、法人和其他组织合法权益,维护社会公共利益,国家互联网信息办公室、工业和信息化部、公安部、国家广播电视总局联合发布《人工智能生成合成内容标识办法》(以下简称),自2025年9月1日起施行。
《标识办法》提出,服务提供者应当按照《互联网信息服务深度合成管理规定》第十六条的规定,在生成合成内容的文件元数据中添加隐式标识,隐式标识包含生成合成内容属性信息、服务提供者名称或者编码、内容编号等制作要素信息。鼓励服务提供者在生成合成内容中添加数字水印等形式的隐式标识。
《标识办法》要求,互联网应用程序分发平台在应用程序上架或者上线审核时,应当要求互联网应用程序服务提供者说明是否提供人工智能生成合成服务。互联网应用程序服务提供者提供人工智能生成合成服务的,互联网应用程序分发平台应当核验其生成合成内容标识相关材料。(来源:人民网)
评论:《标识办法》自2024年9月14日发布征求意见稿,2025年3月14日正式公布,并将自2025年9月1日起施行,同时配套发布的还有《网络安全技术 人工智能生成合成内容标识方法》(GB45438-2025)强制性国家标准。本次《标识办法》正式版与征求意见稿相比基本没有明显变化,已经给各AI服务方及网络平台留足了充分的合规时间。针对《标识办法》的要求,AI服务方应做好如下合规工作:
- 建立完善的标识技术体系。根据《标识办法》及国家标准要求,AI服务方应建立显式标识与隐式标识的技术架构,针对文本、图片、音频、视频等内容进行有效、合理的标识。其中,显式标识应满足如下标准:
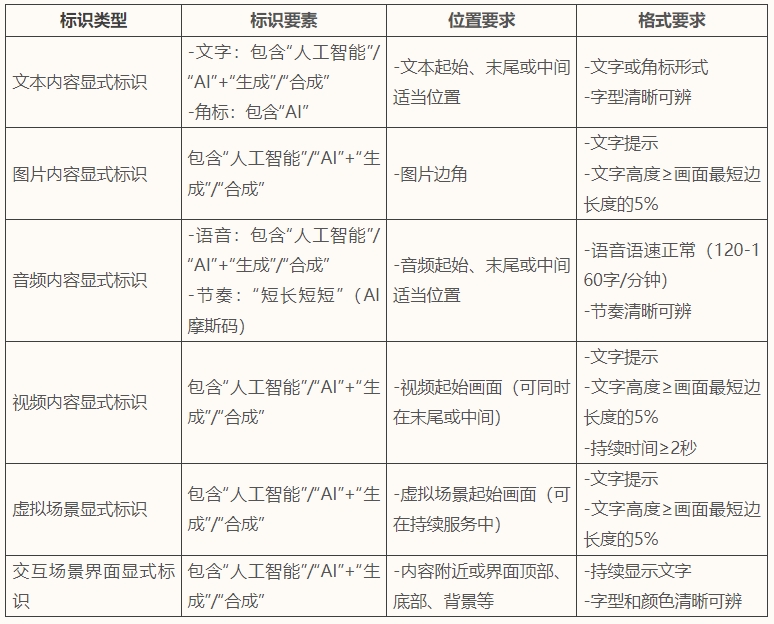
隐式标识应满足如下标准:
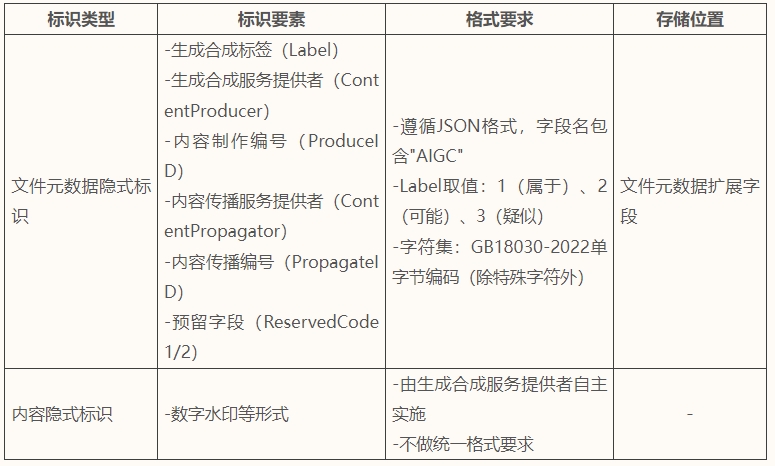
- 更新用户协议。AI服务方应及时更新用户协议,明确将按照法律规定对生成合成内容进行标识,告知用户标识的方法和样式。此外,根据《标识办法》规定,用户可以申请不包含显式标识的内容,则服务方可以根据实际运营情况决定何种情况下向用户开放,但应明确用户的标识义务和使用责任,并建立完善的用户使用日志,至少留存6个月。
- 与第三方建立协作机制。AI服务方应与社交媒体、内容平台、应用分发平台进行技术对接,确保生成内容在传播时保留对应标识,相关标识可识别、可溯源、不可篡改。如涉及第三方开发者,应为第三方开发者提供合规SDK,确保其调用生成接口时自动添加标识,同时双方应在开放平台协议中增加标识责任条款。
2、AI搜索工具错误率高达60%
哥伦比亚大学数字新闻研究中心近期对八款AI搜索引擎进行了深入研究,包括ChatGPT Search、Perplexity及其付费版、Gemini、DeepSeek Search、Grok-2和Grok-3 Search以及Copilot。研究人员从20家新闻机构随机挑选了200篇报道,确保这些文章在谷歌搜索中排名靠前,随后用相同的查询方式测试各AI工具的准确性和引用情况。
结果显示,除Perplexity及其付费版外,其他AI引擎的表现普遍不佳。整体来看,AI提供的答案有60%不准确,且它们往往以绝对肯定的语气陈述错误信息,加剧了问题的严重性。例如,ChatGPT Search虽然回答了所有200个查询,但其完全正确率仅为28%,完全错误率却高达57%。相比之下,X旗下的Grok-3 Search错误率更是达到了惊人的94%。
微软的Copilot也表现欠佳,在200次查询中有104次拒绝作答,而剩下的96次中,仅16次完全正确,总体错误率接近70%。尽管这些问题存在,相关公司并未公开承认,仍继续向用户收取高额订阅费用。(来源:DoNews)
评论:AI搜索的数据污染可能是AI技术发展过程中需要长期面对的问题,特别是AI搜索对海量互联网数据无法有效的区分其可信度及权威性,在很多专业工作中反而优先抓取低质量数据源,导致其搜索推理结果出现明显的问题。最近我们团队在工作中已经发现了AI搜索来源的污染问题,在某些法律研究过程中,AI联网搜索时将网络内某些自媒体发布的明显是AI编造的“垃圾”案例作为可信来源,其推理结果明显与司法实践不一致。而如果将联网搜索关闭,AI凭借深度推理居然能得出正确的结论。如放任不管,错误数据和不准确引用不断地进入用户知识体系,甚至反过来可能被用作进一步训练AI模型的素材,从而在模型更新中加剧“认知偏差”与误信息扩散。希望这个问题可以得到AI开发者及社会各界的关注,我们希望有一个更加良性好用的知识利器,而不是垃圾内容的制造机。‘’
3、用AI写色情小说网上售卖760篇次被判刑
近日,湖北省大冶市人民法院审理了一起利用人工智能(AI)技术撰写色情小说并牟利案件,被告人柯某因犯制作、贩卖、传播淫秽物品牟利罪被判处有期徒刑十个月,并处罚金人民币五千元、退缴违法所得。

公诉机关指控,2022年11月至2023年3月期间,被告人柯某(大专文化,网文作者)以牟利为目的,利用AI程序撰写色情小说,并使用翻墙软件在境外黄色网站发布,同时在另一网站售卖。短短五个月时间,柯某共计发布色情小说数十篇,每篇小说1万字-3万字,每篇15元-30元,总计售卖760篇次,共计获利人民币2万余元。经鉴定,送检的7篇小说均为淫秽物品。
法院经审理认为,被告人柯某以牟利为目的,利用某AI文本生成工具,制作、贩卖、传播淫秽物品,非法获利2万余元,其行为严重违反了我国相关法律法规,对社会风气造成了不良影响,已构成制作、贩卖、传播淫秽物品牟利罪,公诉机关指控罪名成立。被告人柯某到案后能如实供述其犯罪事实、自愿认罪认罚、退缴违法所得,可依法从轻处罚、从宽处理。根据本案犯罪事实、量刑情节、公诉机关量刑建议,法院遂作出上述判决。(来源:人民法院报)
评论:柯某利用AI技术制作、贩卖色情小说案,是我国司法实践中首次明确将AI生成淫秽内容纳入刑事打击范围的典型案例。根据我国刑法第七条规定,属人管辖原则适用于中国公民在境外实施的犯罪行为。柯某虽通过翻墙软件在境外网站发布淫秽内容,但其行为本质上仍受我国刑法约束。本案中,柯某作为具有完全刑事责任能力的中国公民,主观上以牟利为目的,客观上利用AI工具生成并传播淫秽物品,其行为完全符合《刑法》第三百六十三条规定的制作、贩卖、传播淫秽物品牟利罪构成要件。司法机关依据属人管辖原则对其追责,既维护了国家法律尊严,也彰显了我国对公民境外行为的管辖权主张。
柯某的案件也从侧面提醒了国内的AI创业者,技术创新必须与法律风险防控同步推进,即使是完全的出海业务,也应考虑到相应的业务红线,对于色情类、诈骗类、赌博类的业务应该坚决拒绝,技术中立并不等同于法律免责,虚拟的国界也不是刑事责任的天然屏障。唯有将法律规范内化为技术开发的底层逻辑,才能真正实现创业事业的长久发展。
4、美国OpenAI、Google建议美国政府允许其使用受版权保护的材料训练AI模型
美国两大科技巨头OpenAI与谷歌(Google)正敦促美国政府允许其使用受版权保护的材料训练人工智能(AI)模型。这一呼吁是两家公司对美国政府制定国家AI行动计划征询意见的部分回应。该计划旨在明确“优先政策行动”,以维护美国在AI领域的领先地位,并“避免不必要的繁琐要求阻碍私营部门创新”。
谷歌特别强调,需建立兼顾创新与权益的版权法律体系,增设文本与数据挖掘的法定豁免条款。“这些例外条款允许在人工智能训练中合理使用受版权保护的公开材料,既不会显著损害版权持有者权益,也能避免在模型开发或科学实验中陷入漫长且不可预测的版权谈判。”该公司表示。
OpenAI则强调美国版权法中的合理使用的重要性。该原则允许企业和创作者以转化性方式使用版权材料。公司解释称,合理使用原则推动了AI发展,其模型并非复制原始作品,而是通过学习过程创造全新内容。OpenAI反对英国提议的版权制度修改(允许版权持有者选择退出模型训练),认为此类做法构成了AI开发的监管壁垒。(来源:清华大学智能法治研究院)
评论:美国版权法中的合理使用原则是OpenAI的核心法律依据,其法律判断标准为:1)使用目的与性质(是否具有转化性);2)作品性质(是否针对事实性或创造性内容);3)使用数量与实质部分;4)对原作品市场价值的影响。OpenAI主张其AI模型通过转化性使用提取语言模式和结构,但模型的输出并非对原作的替代,而是基于学习的创新成果,不直接复制作品,因此符合合理使用原则的第一项标准。这一主张在美国司法实践中存在争议,例如汤森路透诉AI公司案中,法院认为AI输出可能取代原作市场,因而不属于合理使用。因此,合理使用在美国法项下可能存在较大的法律障碍。
而谷歌提出的“文本与数据挖掘(TDM)豁免条款”建议,旨在为AI训练创设法定例外,该主张的理由是数据挖掘本身不涉及作品传播,而是信息处理行为。此类条款已在欧盟《数字单一市场版权指令》(2019)中部分体现,允许科研机构出于非商业目的使用受版权保护的数据。但谷歌的方案需要国会层面的修订,立法周期长,不确定性更高。
目前,为了巩固自己的技术霸权,欧美部分国家和地区在版权例外方面已开始探索更加宽松和适应新技术发展的路径。美国作为科技创新的重要阵地,需要一个既维护版权人的合法权益,又不阻碍AI和大数据技术的发展的解决方案。但众多创作者及权利人主张AI训练本质上是“系统性掠夺”,短期内阻力依然很大。
- 相关领域
- 高科技与人工智能
