


1、北京查处首例滥用AI技术发布虚假广告案
据“北京市场监管”微信公众号消息,2025年6月,北京市海淀区市场监管局查处了某公司利用AI技术冒用央视知名主持人名义和形象的虚假广告案。
这也是北京市场监管部门运用《中华人民共和国广告法》对滥用AI技术冒用知名人物形象发布虚假广告问题首度“亮剑”。
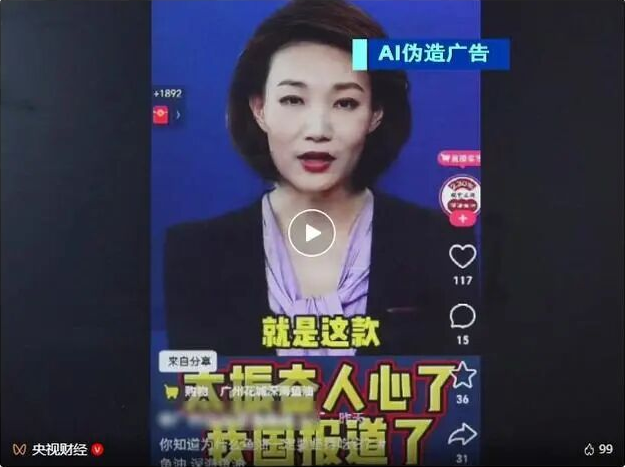
据央视新闻报道,今年2月份,北京市海淀区市场监管局接到消费者举报,反映北京某公司通过视频账号宣传所销售的“深海多烯鱼油”能够治疗多种疾病,涉嫌虚假宣传。
通过举报人提供的视频链接,办案人员打开该企业直播间,在这个拥有88万粉丝的账号直播间展板上,显著标注着“适合头晕头痛、手麻脚麻、记忆下降人群”等医疗用语;直播中还出现了中央广播电视总台主持人李梓萌的形象。
经过立案调查,办案人员发现,该公司销售的深海多烯鱼油产品,实际执行标准为糖果,属于普通食品,不具备疾病治疗功能。另一方面,经鉴定,视频中的主持人形象完全是利用AI技术伪造生成。
该公司违反了《中华人民共和国广告法》相关规定,已接受行政处罚。(来源:网易新闻)
评论:使用AI合成他人肖像进行广告代言是明显的侵权行为,从《民法典》层面,这种肖像使用未经他人许可,严重侵犯了他人肖像权、姓名权等人格权。从《广告法》层面,冒用他人名义和形象进行推荐证明,违反了广告代言需经授权的规定,涉嫌虚假宣传。
本次北京市监部门的首例处罚,意味着从执法层面宣示该等商业模式的“死刑”,可以预见,针对利用AI进行虚假宣传、侵权代言的执法将更加主动和严厉,对类似违法行为的查处将成为常态。除主管部门调查之外,如果使用了明星等知名人士的肖像,相关当事人可能主动的提出维权诉讼,届时企业可能将面临行政处罚、民事赔偿的多重责任。对此,相关企业不应心存侥幸,AI技术应用于降本增效而非歪门邪道。企业应制定内部关于AI技术的合规指引,确保技术应用不触犯法律与伦理底线,宣传如需使用任何第三方人物形象、声音、姓名等元素前,必须获得清晰、完整的书面授权。
2、日本政府要求OpenAI停止侵权
日本政府正式要求OpenAI停止侵权。OpenAI本月初发布了Sora 2,它能以1080p的分辨率生成20秒长度的视频。之后网络上充斥着Sora 2视频,其中很多使用了来自日本流行动漫和游戏中的版权角色,包括来自《海贼王》《鬼灭之刃》《宝可梦》和《马力欧》的角色。日本IP和AI战略大臣Minoru Kiuchi称动漫是日本向世界展示的无可替代的瑰宝。数字大臣Masaaki Taira希望OpenAI能自愿遵守相关版权法。如果问题得不到解决,可能会根据日本AI Promotion Act中的相关措施采取行动。(来源:Solidot)
评论:日本在2019年实施的《著作权法》第30条之4规定了数据分析例外条款,明确以数据分析为目的使用著作权作品,原则上属于权利限制范围,可以不经著作权人许可进行复制和利用。该规定旨在促进日本AI产业的研发和国际竞争力,将训练数据视为“非享受目的”的使用(即计算机在阅读和学习数据,而非人类在欣赏作品),为AI数据训练提供了法定豁免空间。但这种合法性有一个重要的限制条件,即该等训练行为不能不合理地损害著作权人的利益。
本次日本政府的行动针对的不是AI模型的训练过程,而是AI模型的输出结果,即Sora 2生成了使用来自日本流行动漫和游戏中的版权角色的视频。日本政府的行动表明即使训练数据的使用是合法的,但如果最终产品(AI生成的视频)侵犯了著作权人的独创性表达,那这个最终产品的生成和发布行为仍然是侵权行为。这与传统意义上的抄袭判断是一致的,将使得最初训练阶段的豁免条件失效。因此,日本政府目前的行动与之前《著作权法》要求并不矛盾,核心在于要求AI技术提供者采取必要的保护措施,避免日本的文化产业受到直接的冲击及影响。事实上,OpenAI很快发布了Sora版权IP分成政策的公告,似乎是对日本政府行动的响应。但如我们之前分析指出,Sora的新政策的商业模式尚不明确,技术实现也存在很大的复杂性,Sora可能很难因为这一商业上的策略完全摆脱版权的困局。整个AI生成行业也依然会面临持续的版权争议。
3、Reddit联合创始人称大部分互联网已死
Reddit联合创始人Alexis Ohanian对互联网的现状表达了不满,称互联网的很大一部分已死。他指出大部分互联网内容是AI或机器人生成的。他援引了“死亡互联网理论”——即认为互联网的机器人数量超过了活跃的人类数量。他认为需要真实的人才能避免互联网的死亡,认为下一代的社交媒体将会是在群聊基础上发展而来。群组聊天的成员都是由真实的人组成,虽然一部分群聊者也开始使用AI技术去帮助生成和编辑信息。Ohanian称,群聊是黄金标准,但不是新技术,肯定会有下一次迭代,群聊是今天我们所有人获取最佳信息的地方。(来源:Solidot)
4、报告称互联网上逾半数内容是AI生成的
SEO公司Graphite发表了一份报告,称互联网上逾半数内容是AI生成的。Graphite分析了2020年1月至2025年5月间发表的65,000篇英文文章的随机样本,使用了AI检测工具Surfer进行评估,如果一篇文章的内容有五成或更多部分被认为是大模型撰写的,那么这篇文章就被视为是AI生成。分析显示,在ChatGPT于2022年11月发布之后,AI生成文章的数量大幅飙升,其比例从2022年底的10%飙升至2024年的40%以上,之后并趋于平稳。截至今年5月,新AI文章比例为52%。研究人员使用了名叫Common Crawl的开源数据集,该数据集包含了数以千亿计的网页,但由于AI公司利用该数据集训练大模型,很多有付费墙的网站已经屏蔽了Common Crawl,这些网站中人类撰写的文章比例应该更高。此外AI生成的内容农场通常不会被搜索引擎索引或会被降低排名,Graphite发现,Google搜索中86%的文章由人类撰写,AI撰写的比例只有14%。(来源:Solidot)
评论:AI正以前所未有的效率制造着大量数字噪音,AI内容淹没了所有社交平台、短视频平台、阅读平台。很多人已因AI内容的规训,语言逻辑和思考逻辑变得更有“AI味”,互联网正迅速的成为垃圾场。社会公众面对这种泥沙俱下的现状束手无策,只能被动的退回至可信赖的群聊等私域空间,立法者依然在等待所谓的“合适时机”,针对AI噪音,未来的法律监管焦点很有可能将从生成端转向分发端。平台和搜索引擎将不再仅仅是中立渠道,而需承担起信息生态治理者的责任,通过技术与人工审核过滤低质、虚假或侵权的AI内容。因此,建立内容来源追溯机制、明确AIGC的生成标识义务、强化平台的内容审核与注意义务,将是遏制互联网内容生态恶化、保护真实人类创作的关键手段,我们期待这些法律上的治理措施可以尽快落实到位,让互联网重新变得真实、可信。
5、韩国在四个月试用后放弃了AI教科书
韩国在四个月试用后剥夺了AI教科书的正式教材地位,将其归类为“补充材料”。政府在该项目上投入了逾1.2万亿韩元(约8.5亿美元),教科书出版商投入了约8000亿韩元(5.67亿美元)。一度对AI教科书抱有好奇心的学生在使用后表示非常失望,学生、教师和家长抱怨AI教材存在事实错误、数据隐私风险、增加了学生的屏幕时间,加重了师生的负担。是否使用AI教材现在由学校自行决定,其普及率从上学期的37%下降到了秋季学期的19%,目前有2095所学校使用。(来源:Solidot)
评论:AI生成技术可以应用在对结果精确度低的创意行业(比如广告创意、宣传文案等),但显然目前还没有做好进入严肃领域的准备。韩国这堂价值十多亿美元的课,戳破了AI在教育、法律、医疗等严肃领域的应用神话。
这个事件的核心问题在于产品责任与信赖利益的根本性冲突。教科书作为知识传授的核心载体,其内容被默认为是准确、权威的,学生和教师对其有绝对的信赖。然而,当前AI的幻觉是其固有缺陷,它本质上是一个概率模型,而非事实引擎,很多教科书的内容可能都是AI在以绝对自信的口吻“一本正经地胡说八道”。要求不成熟的AI技术,直接进行传道授业解惑,本身就构成了对使用者信赖利益的伤害。更致命的是,这制造了一个巨大的法律责任黑洞:当AI教师传授错误知识,导致学生认知偏差甚至造成更深远的不良影响时,谁来承担法律责任?是算法开发者、内容集成商,还是大力推广的政府?在没有建立起清晰的归责机制和严格的内容审查体系前,任何试图用它取代人类在知识、法律、医疗等关键判断领域的尝试,都无异于一场高风险的社会实验,结果也注定会一片狼藉。
- 相关领域
- 高科技与人工智能
